PyTorch provides the torch.nn module to help us in creating and training of the neural network. We will first train the basic neural network on the MNIST dataset without using any features from these models. We will use only the basic PyTorch tensor functionality and then we will incrementally add one feature from torch.nn at a time.
torch.nn provide us many more classes and modules to implement and train the neural network.
The nn package contains the following modules and classes:
| S.No | Class and Module | Description |
|---|---|---|
| 1. | torch.nn.Parameter | It is a type of tensor which is to be considered as a module parameter. |
| 2. | Containers | |
| 1) torch.nn.Module | It is a base class for all neural network module. | |
| 2) torch.nn.Sequential | It is a sequential container in which Modules will be added in the same order as they are passed in the constructor. | |
| 3) torch.nn.ModuleList | This will holds sub-modules in a list. | |
| 4) torch.nn.ModuleDict | This will holds sub-modules in a directory. | |
| 5) torch.nn.ParameterList | This will holds the parameters in a list. | |
| 6) torch.nn.parameterDict | This will holds the parameters in a directory. | |
| 3. | Convolution layers | |
| 1) torch.nn.Conv1d | This package will be used to apply a 1D convolution over an input signal composed of several input planes. | |
| 2) torch.nn.Conv2d | This package will be used to apply a 2D convolution over an input signal composed of several input planes. | |
| 3) torch.nn.Conv3d | This package will be used to apply a 3D convolution over an input signal composed of several input planes. | |
| 4) torch.nn.ConvTranspose1d | This package will be used to apply a 1D transposed convolution operator over an input image composed of several input planes. | |
| 5) torch.nn.ConvTranspose2d | This package will be used to apply a 2D transposed convolution operator over an input image composed of several input planes. | |
| 6) torch.nn.ConvTranspose3d | This package will be used to apply a 3D transposed convolution operator over an input image composed of several input planes. | |
| 7) torch.nn.Unfold | It is used to extracts sliding local blocks from a batched input tensor. | |
| 8) torch.nn.Fold | It is used to combine an array of sliding local blocks into a large containing tensor. | |
| 4. | Pooling layers | |
| 1) torch.nn.MaxPool1d | It is used to apply a 1D max pooling over an input signal composed of several input planes. | |
| 2) torch.nn.MaxPool2d | It is used to apply a 2D max pooling over an input signal composed of several input planes. | |
| 3) torch.nn.MaxPool3d | It is used to apply a 3D max pooling over an input signal composed of several input planes. | |
| 4) torch.nn.MaxUnpool1d | It is used to compute the partial inverse of MaxPool1d. | |
| 5) torch.nn.MaxUnpool2d | It is used to compute the partial inverse of MaxPool2d. | |
| 6) torch.nn.MaxUnpool3d | It is used to compute the partial inverse of MaxPool3d. | |
| 7) torch.nn.AvgPool1d | It is used to apply a 1D average pooling over an input signal composed of several input planes. | |
| 8) torch.nn.AvgPool2d | It is used to apply a 2D average pooling over an input signal composed of several input planes. | |
| 9) torch.nn.AvgPool3d | It is used to apply a 3D average pooling over an input signal composed of several input planes. | |
| 10) torch.nn.FractionalMaxPool2d | It is used to apply a 2D fractional max pooling over an input signal composed of several input planes. | |
| 11) torch.nn.LPPool1d | It is used to apply a 1D power-average pooling over an input signal composed of several input planes. | |
| 12) torch.nn.LPPool2d | It is used to apply a 2D power-average pooling over an input signal composed of several input planes. | |
| 13) torch.nn.AdavtiveMaxPool1d | It is used to apply a 1D adaptive max pooling over an input signal composed of several input planes. | |
| 14) torch.nn.AdavtiveMaxPool2d | It is used to apply a 2D adaptive max pooling over an input signal composed of several input planes. | |
| 15) torch.nn.AdavtiveMaxPool3d | It is used to apply a 3D adaptive max pooling over an input signal composed of several input planes. | |
| 16) torch.nn.AdavtiveAvgPool1d | It is used to apply a 1D adaptive average pooling over an input signal composed of several input planes. | |
| 17) torch.nn.AdavtiveAvgPool2d | It is used to apply a 2D adaptive average pooling over an input signal composed of several input planes. | |
| 18) torch.nn.AdavtiveAvgPool3d | It is used to apply a 3D adaptive average pooling over an input signal composed of several input planes. | |
| 5. | Padding layers | |
| 1) torch.nn.ReflectionPad1d | It will pad the input tensor using the reflection of the input boundary. | |
| 2) torch.nn.ReflactionPad2d | It will pad the input tensor using the reflection of the input boundary. | |
| 3) torch.nn.ReplicationPad1 | It will pad the input tensor using the replication of the input boundary. | |
| 4) torch.nn.ReplicationPad2d | It will pad the input tensor using the replication of the input boundary. | |
| 5) torch.nn.ReplicationPad3d | It will pad the input tensor using the replication of the input boundary. | |
| 6) torch.nn.ZeroPad2d | It will pad the input tensor boundaries with zero. | |
| 7) torch.nn.ConstantPad1d | It will pad the input tensor boundaries with a constant value. | |
| 8) torch.nn.ConstantPad2d | It will pad the input tensor boundaries with a constant value. | |
| 9) torch.nn.ConstantPad3d | It will pad the input tensor boundaries with a constant value. | |
| 6. | Non-linear activations (weighted sum, non-linearity) | |
| 1) torch.nn.ELU | It will use to apply the element-wise function: ELU(x)=max(0,x)+min(0,α*(exp(x)-1)) | |
| 2) torch.nn.Hardshrink | It will use to apply the hard shrinkage function element-wise function: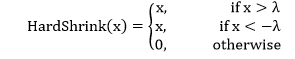 | |
| 3) torch.nn.LeakyReLU | It will use to apply the element-wise function: LeakyReLu(x)=max(0,x) +negative_slope*min(0,x) | |
| 4) torch.nn.LogSigmoid | It will use to apply the element-wise function: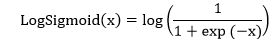 | |
| 5) torch.nn.MultiheadAttention | It is used to allow the model to attend to information from different representation subspaces | |
| 6) torch.nn.PReLU | It will be used to apply the element-wise function: PReLU(x)=max(0,x)+a*min(0,x) | |
| 7) torch.nn.ReLU | It will use to apply the rectified linear unit function element-wise: ReLU(x)=max(0,x) | |
| 8) torch.nn.ReLU6 | It will be used to apply the element-wise function: ReLU6(x)=min(max(0,x),6) | |
| 9) torch.nn.RReLU | It will use to apply the randomized leaky rectified linear unit function, element-wise, as described in the paper: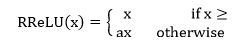 | |
| 10) torch.nn.SELU | It will use to apply the element-wise function as: SELU(x)=scale*(max(0,x)+ min(0,a*(exp(x)-1))) Here α= 1.6732632423543772848170429916717 and scale = 1.0507009873554804934193349852946. | |
| 11) torch.nn.CELU | It will use to apply the element-wise function as: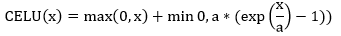 | |
| 12) torch.nn.Sigmoid | It will use to apply the element-wise function as: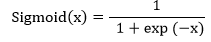 | |
| 13) torch.nn.Softplus | It will use to apply the element-wise function as: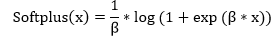 | |
| 14) torch.nn.Softshrink | It will use to apply soft shrinkage function elementwise as: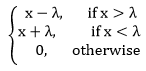 | |
| 15) torch.nn.Softsign | It will use to apply the element-wise function as: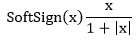 | |
| 16) torch.nn.Tanh | It will use to apply the element-wise function as: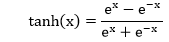 | |
| 17) torch.nn.Tanhshrink | It will use to apply the element-wise function as: Tanhshrink(x)=x-Tanh(x) | |
| 18) torch.nn.Threshold | It will use to thresholds each element of the input Tensor. Threshold is defined as: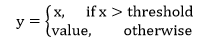 | |
| 7. | Non-linear activations (other) | |
| 1) torch.nn.Softmin | It is used to apply the softmin function to an n-dimensional input Tensor to rescaling them. After that, the elements of the n-dimensional output Tensor lies in the range 0, 1, and sum to 1. Softmin is defined as: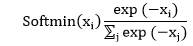 | |
| 2) torch.nn.Softmax | It is used to apply the softmax function to an n-dimensional input Tensor to rescaling them. After that, the elements of the n-dimensional output Tensor lies in the range 0, 1, and sum to 1. Softmax is defined as: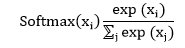 | |
| 3) torch.nn.Softmax2d | It is used to apply SoftMax over features to each spatial location. | |
| 4) torch.nn.LogSoftmax | It is used to apply LogSoftmax function to an n-dimensional input Tensor. The LofSoftmax function can be defined as: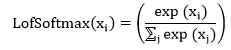 | |
| 5) torch.nn.AdaptiveLogSoftmaxWithLoss | It is a strategy for training models with large output spaces. It is very effective when the label distribution is highly imbalanced | |
| 8. | Normalization layers | |
| 1) torch.nn.BatchNorm1d | It is used to apply batch normalization over a 2D or 3D inputs.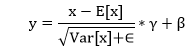 | |
| 2) torch.nn.BatchNorm2d | It is used to apply batch normalization over a 4D.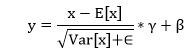 | |
| 3) torch.nn.BatchNorm3d | It is used to apply batch normalization over 5D inputs.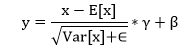 | |
| 4) torch.nn.GroupNorm | It is used to apply group normalization over a mini-batch of inputs. | |
| 5) torch.nn.SyncBatchNorm | It is used to apply batch normalization over n-dimensional inputs. | |
| 6) torch.nn.InstanceNorm1d | It is used to apply an instance normalization over a 3D input. | |
| 7) torch.nn.InstanceNorm2d | It is used to apply an instance normalization over a 4D input. | |
| 8) torch.nn.InstanceNorm3d | It is used to apply an instance normalization over a 5D input. | |
| 9) torch.nn.LayerNorm | It is used to apply layer normalization over a mini-batch of inputs. | |
| 10) torch.nn.LocalResponseNorm | It is used to apply local response normalization over an input signal which is composed of several input planes, where the channel occupies the second dimension. | |
| 9. | Recurrent layers | |
| 1) torch.nn.RNN | It is used to apply a multi-layer Elman RNN with tanh or ReLU non-linearity to an input sequence. Each layer computes the following function for each element in the input sequence: ht=tanh(Wih xt+bih+Whh tt-1+bhh) | |
| 2) torch.nn.LSTM | It is used to apply a multi-layer long short-term memory (LSTM) RNN to an input sequence. Each layer computes the following function for each element in the input sequence: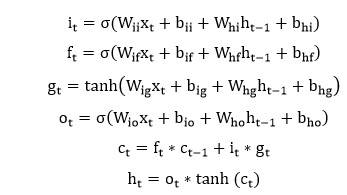 | |
| 3) torch.nn.GRU | It is used to apply a multi-layer gated recurrent unit (GRU) RNN to an input sequence. Each layer computes the following function for each element in the input sequence: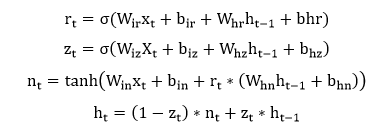 | |
| 4) torch.nn.RNNCell | It is used to apply an Elman RNN cell with tanh or ReLU non-linearity to an input sequence. Each layer computes the following function for each element in the input sequence: h’=tanh(Wih x+bih+Whh h+bhh) ReLU is used in place of tanh | |
| 5) torch.nn.LSTMCell | It is used to apply a long short-term memory (LSTM) cell to an input sequence. Each layer computes the following function for each element in the input sequence: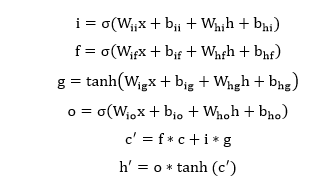 Where σ is the sigmoid function, and * is the Hadamard product. | |
| 6) torch.nn.GRUCell | It is used to apply a gated recurrent unit (GRU) cell to an input sequence. Each layer computes the following function for each element in the input sequence: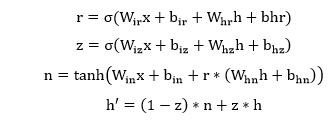 | |
| 10. | Linear layers | |
| 1) torch.nn.Identity | It is a placeholder identity operator which is argument-insensitive. | |
| 2) torch.nn.Linear | It is used to apply a linear transformation to the incoming data: y=xAT+b | |
| 3) torch.nn.Bilinear | It is used to apply a bilinear transformation to the incoming data: y=x1 Ax2+b | |
| 11. | Dropout layers | |
| 1) torch.nn.Dropout | It is used for regularization and prevention of co-adaptation of neurons. A factor of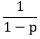 during training scales the output. That means the module computes an identity function during the evaluation. during training scales the output. That means the module computes an identity function during the evaluation. | |
| 2) torch.nn.Dropout2d | If adjacent pixels within feature maps are correlated, then torch.nn.Dropout will not regularize the activations, and it will decrease the effective learning rate. In this case, torch.nn.Dropout2d() is used to promote independence between feature maps. | |
| 3) torch.nn.Dropout3d | If adjacent pixels within feature maps are correlated, then torch.nn.Dropout will not regularize the activations, and it will decrease the effective learning rate. In this case, torch.nn.Dropout2d () is used to promote independence between feature maps. | |
| 4) torch.nn.AlphaDropout | It is used to apply Alpha Dropout over the input. Alpha Dropout is a type of Dropout which maintains the self-normalizing property. | |
| 12. | Sparse layers | |
| 1) torch.nn.Embedding | It is used to store word embedding’s and retrieve them using indices. The input for the module is a list of indices, and the output is the corresponding word embedding. | |
| 2) torch.nn.EmbeddingBag | It is used to compute sums or mean of ‘bags’ of embedding without instantiating the Intermediate embedding. | |
| 13. | Distance Function | |
| 1) torch.nn.CosineSimilarity | It will return the cosine similarity between x1 and x2, computed along dim.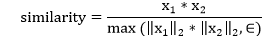 | |
| 2) torch.nn.PairwiseDistance | It computes the batch-wise pairwise distance between vectors v1, v2 using the p-norm: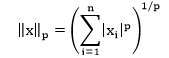 | |
| 14. | Loss function | |
| 1) torch.nn.L1Loss | It is used to a criterion which measures the mean absolute error between each element in the input x and target y. The unreduced loss can be described as: l(x,y)=L={l1,…,ln },ln=|xn-yn |, Where N is the batch size. | |
| 2) torch.nn.MSELoss | It is used to a criterion which measures the mean squared error between each element in the input x and target y. The unreduced loss can be described as: l(x,y)=L={l1,…,ln },ln=(xn-yn)2, Where N is the batch size. | |
| 3) torch.nn.CrossEntropyLoss | This criterion combines nn.LogSoftmax() and nn.NLLLoss() in one single class. It is helpful when we train a classification problem with C classes. | |
| 4) torch.nn.CTCLoss | The Connectionist Temporal Classification loss calculates loss between a continuous time series and a target sequence. | |
| 5) torch.nn.NLLLoss | The Negative Log-Likelihood loss is used to train a classification problem with C classes. | |
| 6) torch.nn.PoissonNLLLoss | The Negative log-likelihood loss with the Poisson distribution of t target~Poisson(input)loss(input,target)=input-target*log(target!)he target. | |
| 7) torch.nn.KLDivLoss | It is a useful distance measure for continuous distribution, and it is also useful when we perform direct regression over the space of continuous output distribution. | |
| 8) torch.nn.BCELoss | It is used to create a criterion which measures the Binary Cross Entropy between the target and the output. The unreduced loss can be described as: l(x,y)=L={l1,…,ln },ln=-wn [yn*logxn+ (1-yn )*log(1-xn)], Where N is the batch size. | |
| 9) torch.nn.BCEWithLogitsLoss | It combines a Sigmoid layer and the BCELoss in one single class. We can take advantage of the log-sum-exp trick for numerical stability by combining the operation into one layer. | |
| 10) torch.nn.MarginRankingLoss | It creates a criterion which measures the loss of given inputs x1, x2, two 1D mini-batch Tensors, and a label 1D mini-batch tensor y which contain 1 or -1. The loss function for each sample in the mini-batch is as follows: loss(x,y)=max(0,-y*(x1-x2 )+margin | |
| 11) torch.nn.HingeEmbeddingLoss | HingeEmbeddingLoss measures the loss of given an input tensor x and a labels tensor y which contain 1 or -1. It is used for measuring whether two inputs are similar or dissimilar. The loss function is defined as: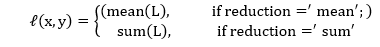 | |
| 12) torch.nn.MultiLabelMarginLoss | It is used to create a criterion which optimizes a multi-class multi-classification hinge loss between input x and output y.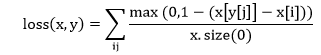 | |
| 13) torch.nn.SmoothL1Loss | It is used to create a criterion which uses a squared term if the absolute element-wise error falls below 1 and an L1 term otherwise. It is also known as Huber loss: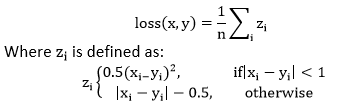 | |
| 14) torch.nn.SoftMarginLoss | It is used to create a criterion which optimizes the two-class classification logistic loss between input tensor x and target tensor y which contain 1 or -1.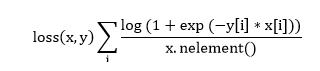 | |
| 15) torch.nn.MultiLabelSoftMarginLoss | It is used to create a criterion which optimizes the multi-label one-versus-all loss based on max-entropy between input x and target y of size (N, C).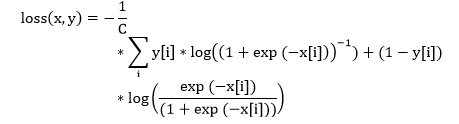 | |
| 16) torch.nn.CosineEmbeddingLoss | It is used to create a criterion which measures the loss of given input tensors x1, x2 and a tensor label y with values 1 or -1. It is used for measuring whether two inputs are similar or dissimilar, using the cosine distance.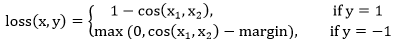 | |
| 17) torch.nn.MultiMarginLoss | It is used to create a criterion which optimizes a multi-class classification hinge loss between input x and output y.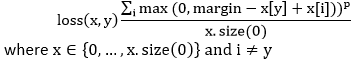 | |
| 18) torch.nn.TripletMarginLoss | It is used to create a criterion which measures the triplet loss of given an input tensors x1, x2, x3 and a margin with a value greater than 0. It is used for measuring a relative similarity between samples. A triplet is composed of an anchor, positive example, and a negative example. L(a,p,n)=max{d(ai,pi )-d(ai,ni )+margin,0} | |
| 15. | Vision layers | |
| 1) torch.nn.PixelShuffle | It is used to re-arrange the elements in a tensor of shape(*,C×r2,H,W) to a tensor of shape (*,C,H×r,W,r) | |
| 2) torch.nn.Upsample | It is used to upsample a given multi-channel 1D, 2D or 3D data. | |
| 3) torch.nn.upsamplingNearest2d | It is used to apply 2D nearest neighbor upsampling to an input signal which is composed with multiple input channel. | |
| 4) torch.nn.UpsamplingBilinear2d | It is used to apply 2D bilinear upsampling to an input signal which is composed with, multiple input channel. | |
| 16. | DataParallel layers(multi-GPU, distributed) | |
| 1) torch.nn.DataParallel | It is used to implement data parallelism at the module level. | |
| 2) torch.nn.DistributedDataParallel | It is used to implement distributed data parallelism, which is based on the torch.distributed package at the module level. | |
| 3) torch.nn.DistributedDataParallelCPU | It is used to implement distributed data parallelism for the CPU at the module level. | |
| 17. | Utilities | |
| 1) torch.nn.clip_grad_norm_ | It is used to clip the gradient norm of an iterable of parameters. | |
| 2) torch.nn.clip_grad_value_ | It is used to clip the gradient norm of an iterable of parameters at the specified value. | |
| 3) torch.nn.parameters_to_vector | It is used to convert parameters to one vector. | |
| 4) torch.nn.vector_to_parameters | It is used to convert one vector to the parameters. | |
| 5) torch.nn.weight_norm | It is used to apply weight normalization to a parameter in the given module.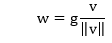 | |
| 6) torch.nn.remove_weight_norm | It is used to remove the weight normalization and re-parameterization from a module. | |
| 7) torch.nn.spectral_norm | It is used to apply spectral normalization to a parameter in the given module. | |
| 8) torch.nn.PackedSequence | It will use to hold the data and list of batch_sizes of a packed sequence. | |
| 9) torch.nn.pack_padded_sequence | It is used to pack a Tensor containing padded sequences of variable length. | |
| 10) torch.nn.pad_packed_sequence | It is used to pads a packed batch of variable-length sequences. | |
| 11) torch.nn.pad_sequence | It is used to pad a list of variable length Tensors with padding value. | |
| 12) torch.nn.pack_sequence | It is used to packs a list of variable length Tensors | |
| 13) torch.nn.remove_spectral_norm | It is used to removes the spectral normalization and re-parameterization from a module. |
Leave a Reply